sed与awk是可以单独出书的两个Linux命令,它们的功能非常强大,本章节将分别介绍着两个命令。其中sed使用的是gnu-sed 4.2.2版本,对应下文中出现的gsed,而不是Mac自带的sed。awk同样使用gnu版本的awk,对应文中出现的gawk。
1. sed命令(Mac)
sed是Linux中的一个文件编辑工具,按行处理文件内容,可以实现插入,删除,替换等功能。更重要的是sed命令可以用script来处理文本文件,能够应对复杂的编辑需求。
sed命令语法
基本格式 sed [option] [filename]
选项:
-e <script>按script编辑文本并输出到控制台,但不修改原文件内容-f filename调用sed脚本文件-i直接修改读取的文件内容,而不输出到终端-n使用安静模式,只有经过sed处理的行才会被显示出来-r使用延伸型的正则表达式语法,预设的是基础的正则语法
动作命令[n1[,n2]] function
n1,n2表示起始行和结束行,不一定存在,而function表示动作行为
常用function命令:
a新增一行内容(在指定行的下一行)c取代内容,可取代n1,n2之间的行d删除行i插入一行内容(在指定行的上一行)p列印,将某个选择的资料印出,常与sed -n连用s取代,搭配正则表达式,替换文本中的内容
sed命令示例
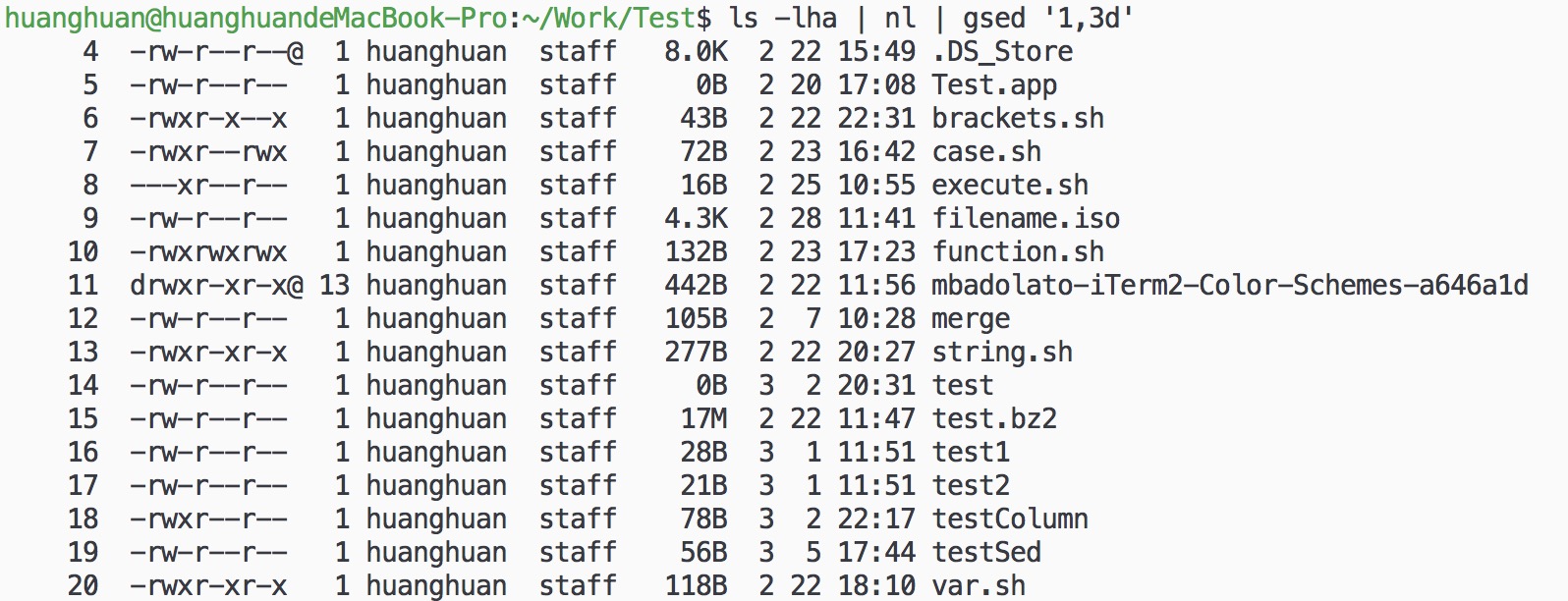
1. 行的删除:`
ls -lha | nl | gsed '1,3d'
删除输出中的第1到第3行,此时参数-e可不加。
2. 行的插入:
a. 在指定行前插入
gsed '4a 插入的第一行\n插入的第二行' testSed
b. 在指定行后插入
gsed '1i 插入的第一行\n插入的第二行' testSed
若要让操作更新到原文件中,需加-i,该操作较为危险。建议使用
gsed -i.bak '1i test' testSed
这样的执行方式,通过这种方式可额外生成testSed.bak文件,该文件保存了原始内容,这样更安全。

3. 行的选择性显示:
有时会显示文件中某个区间内容的需求,这时通过gsed -n可以做到:
gsed -n '2,$p' testSed

4. 搜索并执行命令:
a. 搜索含有关键字的行:
gsed -n '/^第.行/p' testSed

b. 搜索并删除:
gsed '/第四行/d' testSed

c. 执行多组命令:
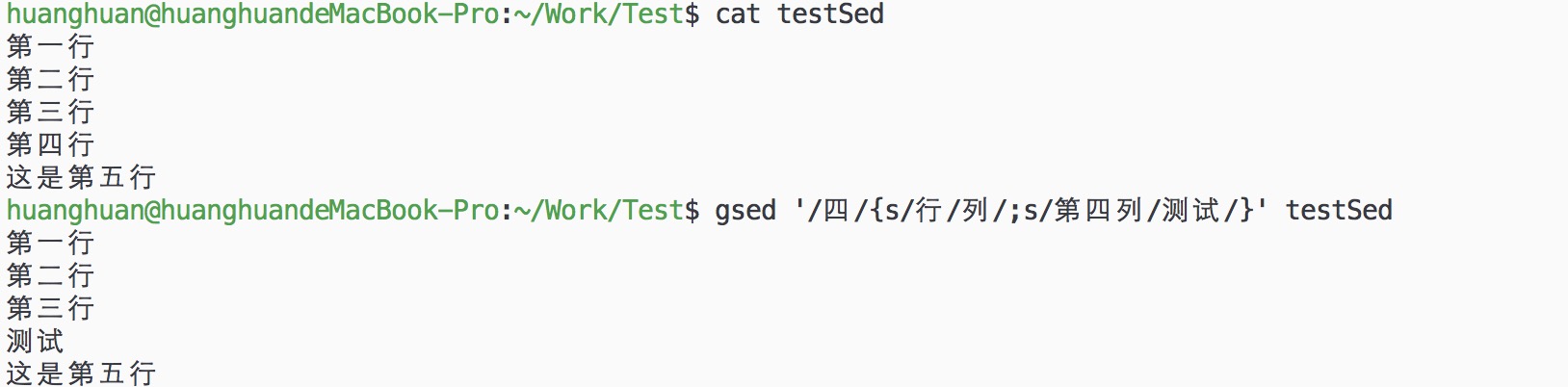
gsed '/四/{s/行/列/;s/第四列/测试/}' testSed
s表示替换,从图中的结果可以看到,这个过程有点类似SQL的where查询,后面的命令在前面的执行结果下执行。
5. 内容替换:
a. 区域替换:
gsed '2,3c 替换内容' testSed

b. 搜索替换:
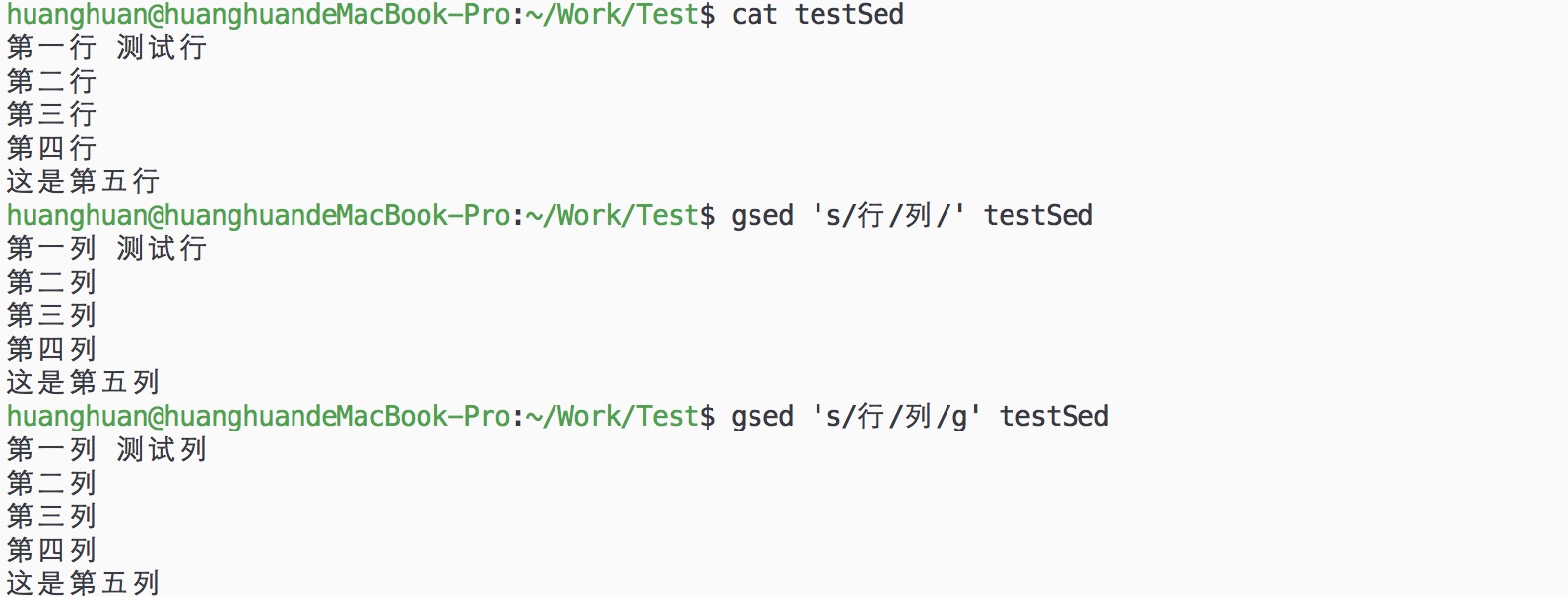
gsed 's/行/列/g' testSed
如果没有g则只替换行内匹配的第一个
6. 多重编辑:
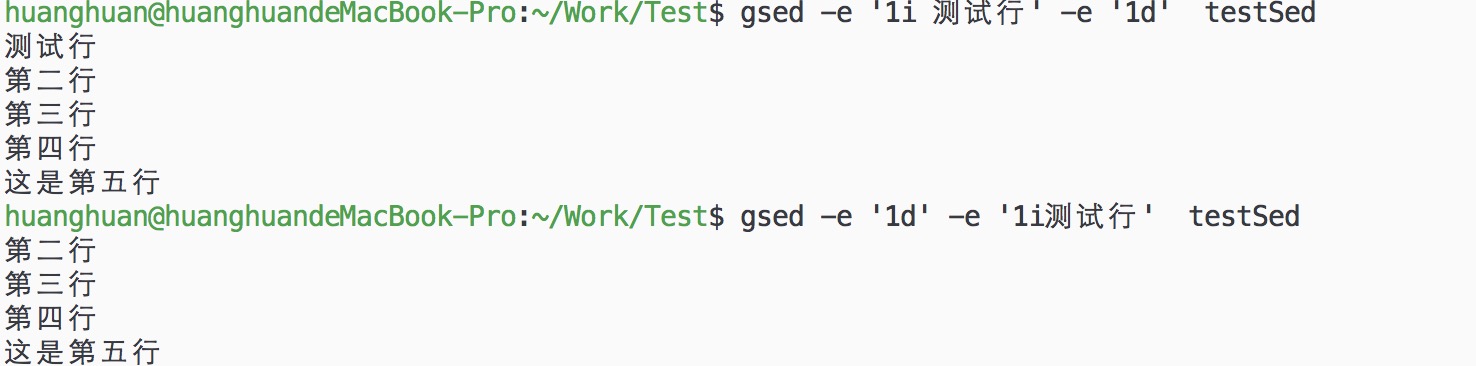
gsed -e '1i 测试行' -e '1d' testSed
gsed -e '1d' -e '1i测试行' testSed
从图中可以看到两者执行的区别,由于sed是按行读入缓冲区,处理后再读如下一行,所以多重编辑时命令的顺序对结果有影响。
2. awk (Mac)
awk时非常强大的文本分析工具,非常适用于生成分析报告。awk会将文本逐行的读入,默认以空格或制表符为分隔符进行切片,然后对切片后的部分分析处理。awk十分强大,实际上它也有自己的编程语言:“样式扫描和处理语言”,其名称源自于创始人Alfred Aho,Peter Weinberger,Brian Kernighan。
awk语法
基本格式 awk [option] '[pattern][codeblock]' [filenames]
codeblock表示代码块区域
-F指定域分隔符-f调用脚本-v定义变量
awk代码块表示方法
awk中的BEGIN,END:
BEGIN {} // { statement one; statement two} END {}
BEGIN初始代码块//匹配代码块,与sed中的用法类似{}命令代码块,包含多条命令语句,用;分隔END结尾代码块,在每一行执行完后运行。
awk中的条件语句与C语言相同,支持while,for,break,continue:
if( condition expression ){
statement one;
}else if ( condition expression ){
statement two;
}else{
statement three;
}
awk中的数组表示方式为array[key],其中key 可以是字母或数字,其内部实际上是用hash的方式存储。
awk内置变量
0表示当前行所有内容,n第n个域的内容,用$取值ARGC命令行参数个数ARGV命令行参数排列ENVIRON支持队列中系统的环境变量使用FILENAME正在浏览的文件名FNR浏览文件的记录数FS设置输入域的分隔符,等价于-F选项,在BEGIN时定义NF域的个数NR已经读取的记录个数OFS输出域分隔符ORS输出记录分隔符RS控制记录分隔符
awk内置函数
cos(x),sin(x),sqrt(x),rand()等算数类函数sub(),index(),length(),substr(),sprintf(),split()等字符串函数getline(),system(),close(),mktime(),systime()等其它函数function funcName(){}自定义函数
详细内容参考:awk内部函数
awk示例
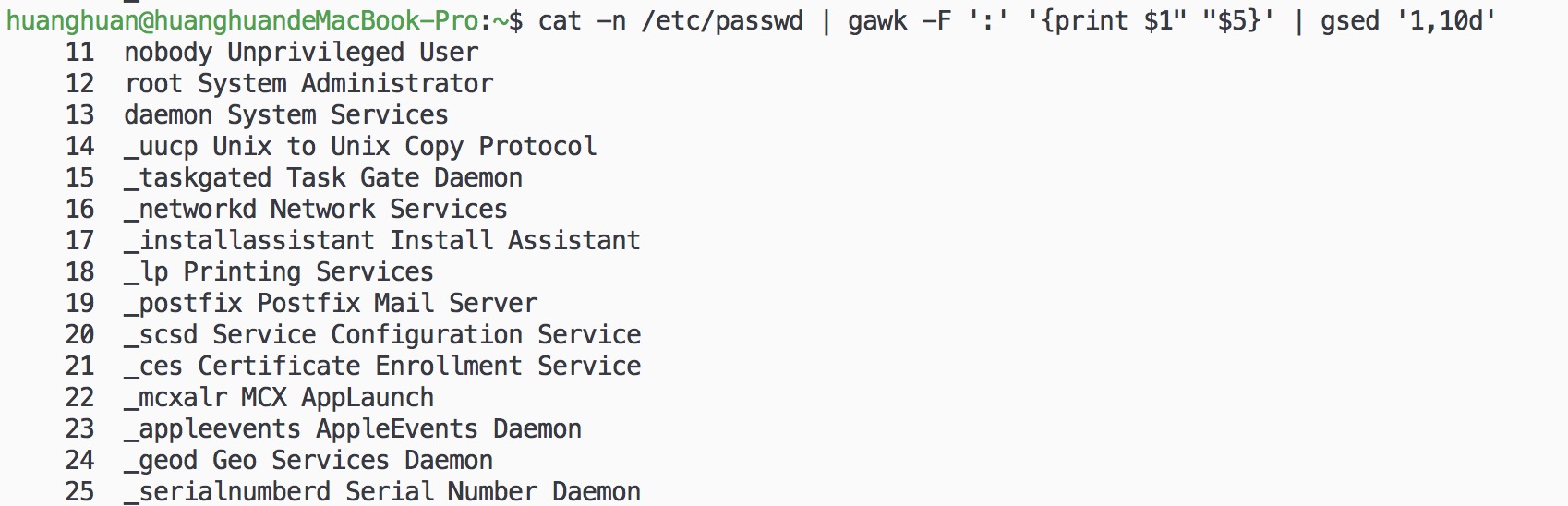
1. 打印账户和账户对应的shell:
cat -n /etc/passwd | gawk -F ':' '{print $1" "$5}' | gsed '1,10d'
其中$1和$5分别表示分割后的第一个和第五个域。
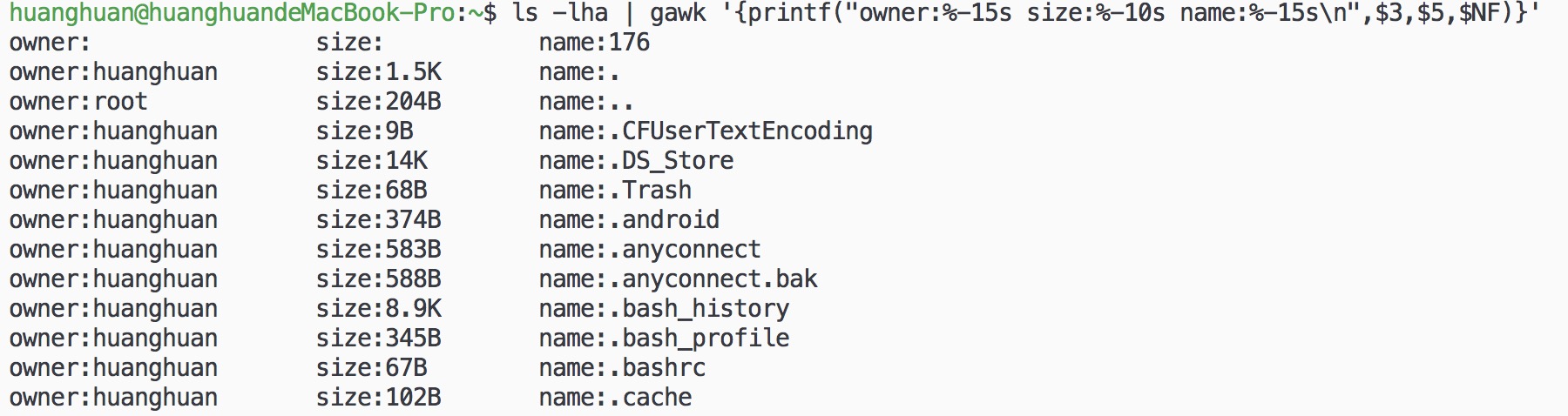
2. 使用printf:
ls -lha | gawk '{printf("owner:%-15s size:%-10s name:%-15s\n",$3,$5,$NF)}'
类似C语言的printf。
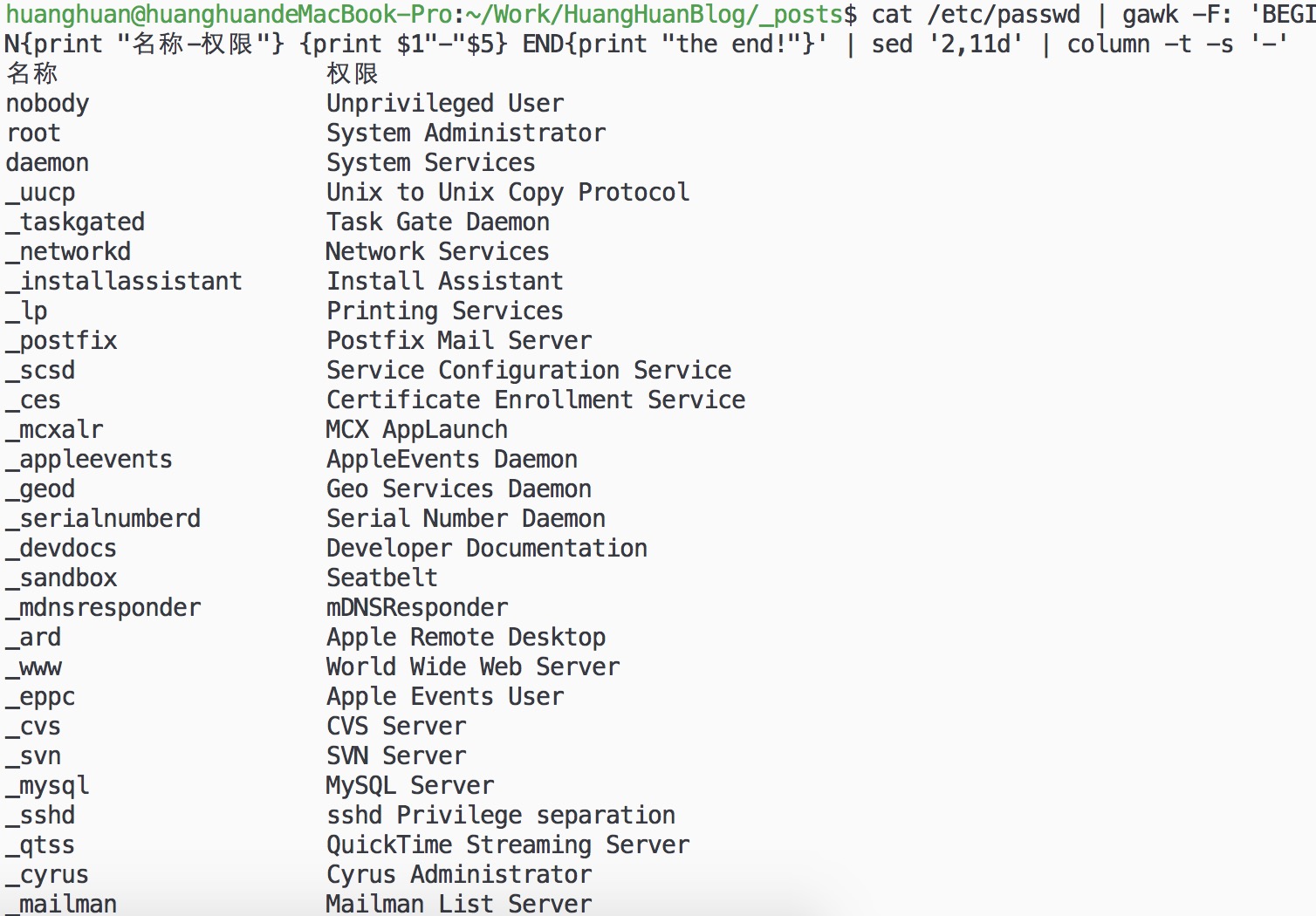
3. 使用Begin End:
cat /etc/passwd | gawk -F: 'BEGIN{print "名称-权限"} {print $1"-"$5} END{print "the end!"}' | sed '2,11d' | column -t -s '-'
4. awk中模式匹配的使用:
cat -n /etc/passwd | gawk -F: '/System/{print $1" "$5}'
搜索包含System关键字的行并输出。

5. 统计文件夹下的文件数目:
ls -lha | gawk 'BEGIN {count=0} {count++} END { print "File Count:"count}'
最好在BEGIN中初始化变量

6. 输出文件夹下大小小于200B的文件名称:
ls -l | gawk 'BEGIN{i=0} {if(NF>=5&&$5<200){filename[i++]=$9;}} END{print "total:"i;for(j=0;j<i;j++){print "filename:"filename[j];}}'
在调用某个域的值之前,需要先判断该域是否存在,此时用NF值。
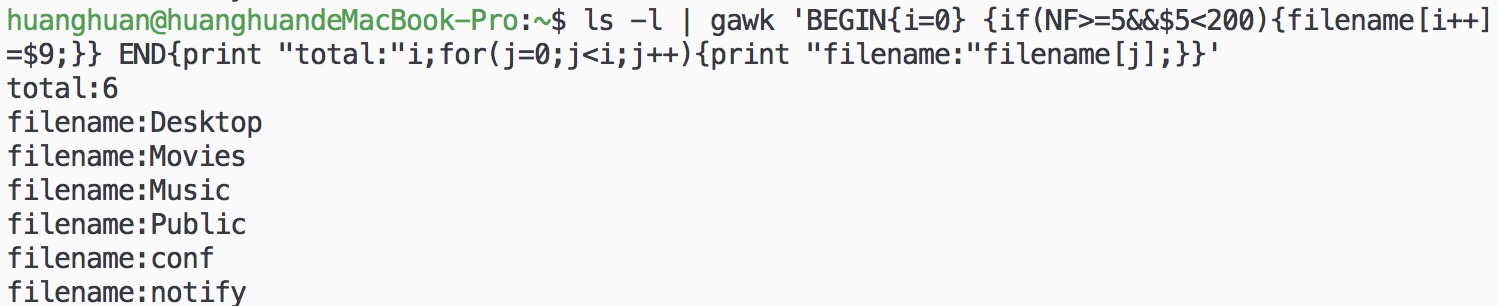
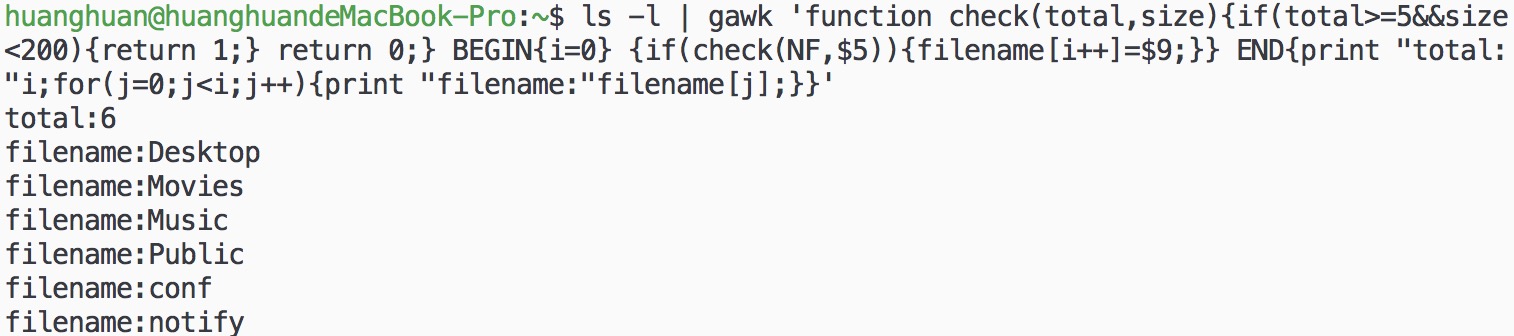
7. 调用自定义函数实现范例6中的功能:
ls -l | gawk 'function check(total,size){if(total>=5&&size<200){return 1;} return 0;} BEGIN{i=0} {if(check(NF,$5)){filename[i++]=$9;}} END{print "total:"i;for(j=0;j<i;j++){print "filename:"filename[j];}}'