Zookeeper是Apache Hadoop的一个子项目,本质是一个分布式小文件系统,主要解决分布式系统应用中遇到的数据管理问题(一致性问题):统一命名服务,状态同步服务,集群管理,分布式应用配置项的管理。
1. 数据结构
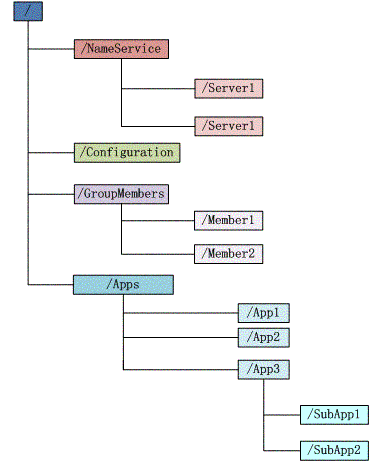
- 每个子目录项(比如图中的NameService)都被称为znode。
- znode可以有子节点目录,并且每个znode都可以保存数据,但注意EPHEMERAL类型的目录节点不能有子节点目录。
- znode是有版本的,每个znode中存储的数据可以有多个版本,也就是同一访问路径可以存储多份数据。
- 对于临时的znode,一旦创建这个znode的客户端与服务器失去联系,这个znode也将自动删除,Zookeeper的客户端和服务器通信采用长链接方式,每个客户端和服务器通过心跳来保持连接。
- znode可以被监控,包括这个节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知监听的客户端,这个是Zookeeper的重要特性。
2. 节点
Zookeeper有四种类型的节点:
- PERSISTENT
- PERSISTENT_SEQUENTIAL
- EPHEMERAL
- EPHEMERAL_SEQUENTIAL
节点在创建后其类型不能被修改。
2.1 简单封装
/**
* Zookeeper测试类
* Created by huanghuan on 2017/2/8.
*/
@Log
public class ZookeepeTest {
private ZooKeeper zooKeeper;
public ZooKeeper connect(String host) throws Exception {
zooKeeper = new ZooKeeper(host, 2181, watchedEvent -> {
log.info("# connect " + watchedEvent.toString());
});
return zooKeeper;
}
public void close() throws InterruptedException {
zooKeeper.close();
}
public String createNode(String path, byte[] data, CreateMode createMode)
throws Exception {
zooKeeper.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, createMode);
}
public void deleteNode(String path) throws Exception {
zooKeeper.delete(path, zooKeeper.exists(path, true).getVersion());
}
public Stat watch(String path) throws KeeperException, InterruptedException {
Stat stat = new Stat();
zooKeeper.getData(path, watchedEvent -> {
log.info("# event " + watchedEvent.toString());
}, stat);
return stat;
}
}2.2 创建节点
public static void main(String args[]) throws Exception {
ZookeeperTest zookeeperTest=new ZookeeperTest();
zookeeperTest.connect("127.0.0.1");
log.info(zookeeperTest.createNode("/test", "test".getBytes(),
CreateMode.PERSISTENT));
for (int i = 0; i < 5; i++) {
log.info(zookeeperTest.createNode("/test/child", null,
CreateMode.PERSISTENT_SEQUENTIAL));
}
}结果为:
信息: /test
信息: /test/child0000000000
信息: /test/child0000000001
信息: /test/child0000000002
信息: /test/child0000000003
信息: /test/child0000000004临时节点的创建原理类似,但在客户端断开连接后,临时节点的内容将消失。
2.3 监听节点。
public static void main(String args[]) throws Exception {
ZookeeperTest zookeeperTest = new ZookeeperTest();
zookeeperTest.connect("127.0.0.1");
zookeeperTest.createNode("/test/watch", "watch".getBytes(),
CreateMode.PERSISTENT);
zookeeperTest.watch("/test/watch");
zookeeperTest.deleteNode("/test/watch");
}结果为:
信息: # connect WatchedEvent state:SyncConnected type:None path:null
信息: # connect WatchedEvent state:SyncConnected type:NodeDeleted path:/test/watch
信息: # event WatchedEvent state:SyncConnected type:NodeDeleted path:/test/watch3. 集群
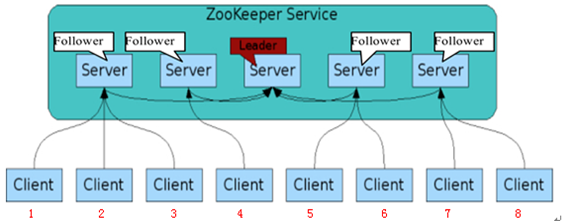
3.1 角色
Zookeeper集群中包含三个角色:
- Leader: 负责进行投票的发起和决议,更新系统的状态,为客户端提供读和写服务。
- Follower: 用于接受客户端请求并且向客户端返回结果,同时在选主过程中参与投票,为客户端提供读服务。
- Observer: 实际上是不参加投票的Follower,用于扩展系统。
其中Follower和Observer统称为Learner,
3.2 读写模式
在一个Zookeeper集群中,读写操作可以发生在任何一个集群角色上,而写的请求都会被转发到Leader,然后Leader通过Zookeeper中的原子广播协议(ZAB协议,可以理解为Paxos协议的一种简化形式),将请求广播给所有的Learner,当Leader收到一半以上的写成功ACK后,就认为该写操作成功了,则将该操作持久化,并告诉客户端。
3.3 ZAB协议
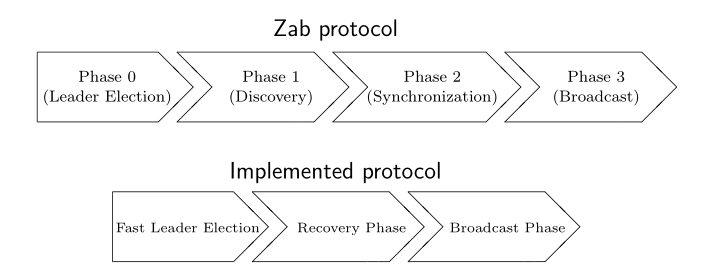
ZAB(Atomic broadcast protocol)协议是为Zookeeper专门设计的支持恢复崩溃的原子广播协议,它是Zookeeper实现分布式数据一致性的基础,基于此,Zookeeper实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
3.3.1 Quorum
Quorum名词解释: 集群中超过半数的节点集合。
之所以Zookeeper的写操作只需要半数以上的写成功ACK后,就认为该操作成功,是因为ZAB协议中的Quorum机制。
Quorum解决的是Read Only Write All带来的写性能问题,能够不需要更新全部数据,但又保证返回给用户的是有效数据。 Quorum的关键在于更新多少个数据副本,使得读取时总能够取到有效数据。假设一共有N个副本,其中k个已经更新,N-k个未更新,那么只要读取集群中N-k+1个数据,就一定能读到最新的数据(前文提到,znode是具有版本的,选取其中版本最新的即可)。
所以从这里可以看到,Quorum机制为Zookeeper的读写提供了一种调整的可能,在读和写性能中做tradeoff。
3.3.2 四个阶段
注意Zookeeper中的Observer和ZAB协议没有关系。
第一阶段:Leader election(选举阶段)
最初时,所有节点都处于选举阶段,当其中一个节点得到了超过了半数节点的票数,它才能当选准Leader。只有达到第三阶段,准Leader才回变成实际的Leader。这一阶段Zookeeper使用的算法有Fast Leader Election。
第二阶段:Discovery(发现阶段)
这个阶段中,Followers和准Leader进行通信,同步Followers最近最近接收的事务提议。这一阶段的主要目的是发现当前大多数节点接受的最新提议,并让Followers接收准Leader定义的epoch(相当于朝代号,每一代Leader会有自己的epoch)。
第三阶段:Synchronization(同步阶段)
同步阶段主要是利用Leader前一阶段获得的最新提议历史,同步集群中的所有副本。只有当Quorum都同步完成,准Leader才回称为真的Leader。
第四阶段:Broadcast(广播阶段)
这个阶段Zookeeper才能够正式对外提供事务服务,并且Leader可以进行消息广播。
3.3.3 2N+1
Zookeeper有这么一个特性:集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的 ,所以容错性上讲,2N和2N-1的容错性都是N-1,而2N+1的容错性为N,所以一般推荐节点数配置为奇数个。为什么会有这样一个特性了?因为Zookeeper的大多数行为都是基于投票的,需要半数以上的节点同意才能执行。
The rationale for having an odd number is Zookeeper always requires a majority of the nodes in the Zookeeper cluster to agree on any change. This means that any number of nodes less than half can fail and Zookeeper can still function. For example, if you have 4 nodes configured, you can only suffer one failure and still continue operating. If you have two failures, then the 2 remaining nodes can never by greater than half (since they are exactly half) of the nodes. This is no better than with three nodes. Also, since the chance of two failures in four nodes is slightly more likely than the chance of two failures in three nodes, this would not be favorable.